Lijian Li
 M.S., University of Macau (Now)
M.S., University of Macau (Now)
 B.S., Southwest University (2023)
B.S., Southwest University (2023)
I am currently a Master student at the Faculty of Science and Technology, University of Macau, under the supervision of Prof. Chi-Man Pun. Previously, I earned my B.S. degree in Software Engineering from Southwest University. My research interests cover Multi-modal Learning, AI-Generated Content, Trustworthy Machine Learning, and Semi-supervised Learning.

Education
-
University of Macau
M.S. in Faculty of Computer and Technology Sep. 2023 - Now
-
Southwest University
B.S. in Software Engineering Sep. 2019 - Jul. 2023
Experience
-

Guangming Laboratory
Research Intern Aug. 2024 - Now
Selected Publications (view all )
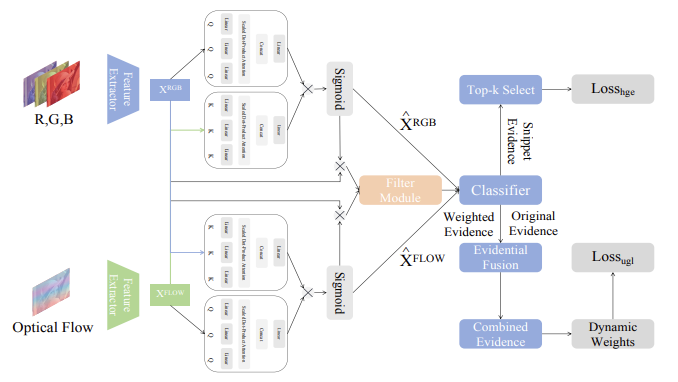
Generalized Uncertainty-Based Evidential Fusion with Hybrid Multi-Head Attention for Weak-Supervised Temporal Action Localization
Yuanpeng He, Lijian Li, Tianxiang Zhan, Wenpin Jiao, Chi-Man Pun
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024) 2024 CCF B Regular Paper (Oral)
Capturing feature information effectively is of great importance in the field of computer vision. With the development of convolutional neural networks, concepts like residual connection and multiple scales promote continual performance gains in diverse deep learning vision tasks. In this paper, novel residual feature-reutilization inception and split-residual feature-reutilization inception are proposed to improve performance on various vision tasks. It consists of four parallel branches, each with convolutional kernels of different sizes. These branches are interconnected by hierarchically organized channels, similar to residual connections, facilitating information exchange and rich dimensional variations at different levels. This structure enables the acquisition of features with varying granularity and effectively broadens the span of the receptive field in each network layer. Moreover, according to the network structure designed above, split-residual feature-reutilization inceptions can adjust the split ratio of the input information, thereby reducing the number of parameters and guaranteeing the model performance. Specifically, in image classification experiments based on popular vision datasets, such as CIFAR10 (97.94%), CIFAR100 (85.91%), Tiny Imagenet (70.54%) and ImageNet (80.83%), we obtain state-of-the-art results compared with other modern models under the premise that the models’ sizes are approximate and no additional data is used.
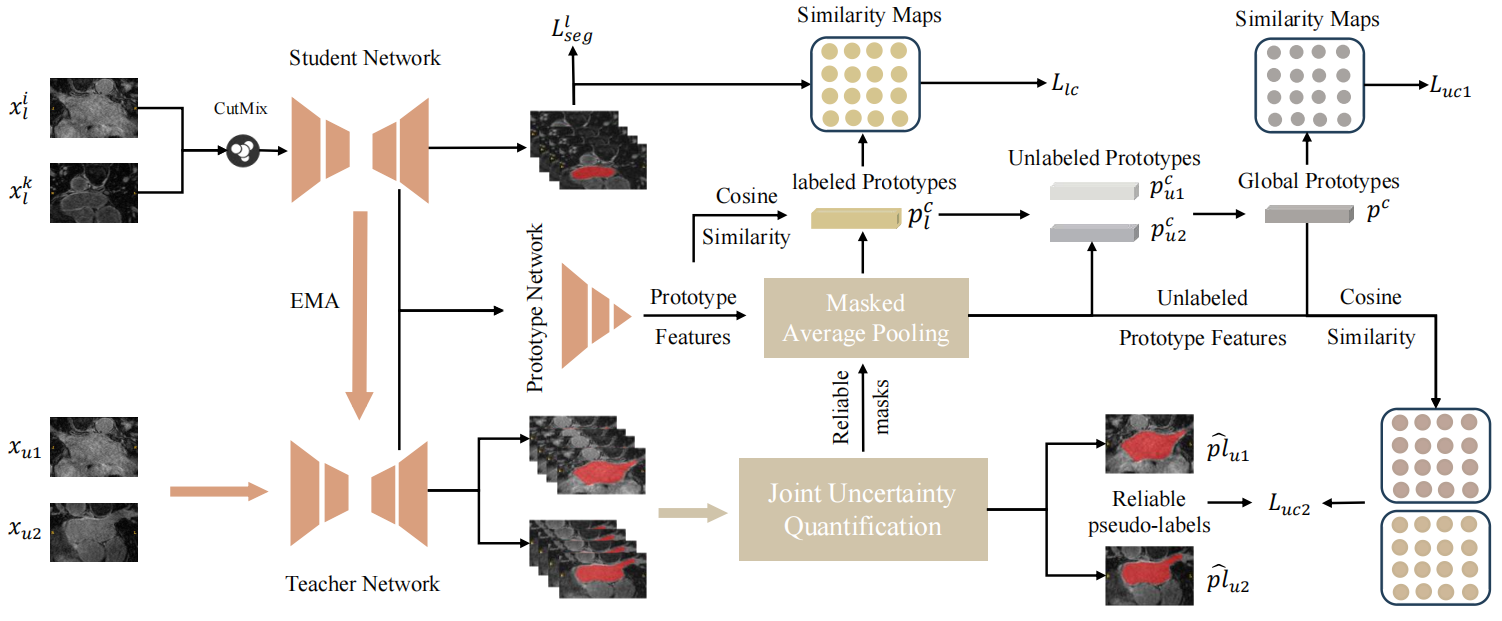
Efficient Prototype Consistency Learning in Semi-Supervised Medical Image Segmentation via Joint Uncertainty and Data Augmentation
Lijian Li, Yuanpeng He, Chi-Man Pun
IEEE International Conference on Bioinformatics and Biomedicine 2024 (IEEE BIBM 2024) 2024 CCF B Regular Paper
Recently, prototype learning has emerged in semi-supervised medical image segmentation and achieved remarkable performance. However, the scarcity of labeled data limits the expressiveness of prototypes in previous methods, potentially hindering the complete representation of prototypes for class embedding. To overcome this issue, we propose an efficient prototype consistency learning via joint uncertainty quantification and data augmentation (EPCL-JUDA) to enhance the semantic expression of prototypes based on the framework of Mean-Teacher. The concatenation of original and augmented labeled data is fed into student network to generate expressive prototypes. Then, a joint uncertainty quantification method is devised to optimize pseudo-labels and generate reliable prototypes for original and augmented unlabeled data separately. High-quality global prototypes for each class are formed by fusing labeled and unlabeled prototypes, which are utilized to generate prototype-to-features to conduct consistency learning. Notably, a prototype network is proposed to reduce high memory requirements brought by the introduction of augmented data. Extensive experiments on Left Atrium, Pancreas-NIH, Type B Aortic Dissection datasets demonstrate EPCL-JUDA's superiority over previous state-of-the-art approaches, confirming the effectiveness of our framework. The code will be released soon.

NNDF A new neural detection network for aspect-category sentiment analysis
Lijian Li, Yuanpeng He, Li Li
International Conference on Knowledge Science, Engineering and Management (KSEM) 2022 CCF C
Aspect-category sentiment analysis (ACSA) is crucial for capturing and understanding sentiment polarities of aspect categories hidden behind in sentences or documents automatically. Nevertheless, existing methods have not modeled semantic dependencies of aspect terms and specified entity’s aspect category in sentences. In this paper, we propose a New Neural Detection Network, named NNDF in short, to enhance the ACSA performance. Specifically, representations of input sentences and aspect categories contained in our method are generated by a CNN-pooling-BiLSTM structure respectively, where sentences are represented based on their contextual words and aspect categories are represented based on word embeddings of entities category-specific. Then, a Transformer-based encoder is used to model implicit dependency of sentence contexts and aspect categories of entities in sentences. Finally, the embedding of aspect-category is learned by the novel bidirectional attention mechanism for the sentiment classification. Besides, experiments conducted on Restaurant and MAMS benchmark datasets for the task demonstrate that NNDF achieves more accurate prediction results as compared to several state-of-the-art baselines.