2024

Towards Realistic Long-tailed Semi-supervised Learning in an Open World
arXiv 2024 Preprint
Open-world long-tailed semi-supervised learning (OLSSL) has increasingly attracted attention. However, existing OLSSL algorithms generally assume that the distributions between known and novel categories are nearly identical. Against this backdrop, we construct a more \emph{Realistic Open-world Long-tailed Semi-supervised Learning} (\textbf{ROLSSL}) setting where there is no premise on the distribution relationships between known and novel categories. Furthermore, even within the known categories, the number of labeled samples is significantly smaller than that of the unlabeled samples, as acquiring valid annotations is often prohibitively costly in the real world. Under the proposed ROLSSL setting, we propose a simple yet potentially effective solution called dual-stage post-hoc logit adjustments. The proposed approach revisits the logit adjustment strategy by considering the relationships among the frequency of samples, the total number of categories, and the overall size of data. Then, it estimates the distribution of unlabeled data for both known and novel categories to dynamically readjust the corresponding predictive probabilities, effectively mitigating category bias during the learning of known and novel classes with more selective utilization of imbalanced unlabeled data. Extensive experiments on datasets such as CIFAR100 and ImageNet100 have demonstrated performance improvements of up to 50.1\%, validating the superiority of our proposed method and establishing a strong baseline for this task. For further researches, the anonymous link to the experimental code is at \href{this https URL}{\textcolor{brightpink}{this https URL}}
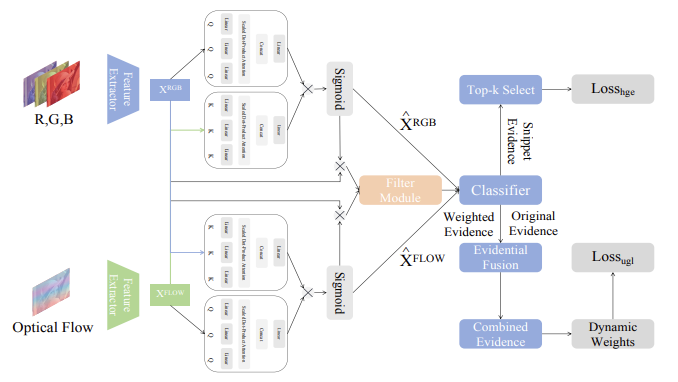
Generalized Uncertainty-Based Evidential Fusion with Hybrid Multi-Head Attention for Weak-Supervised Temporal Action Localization
Yuanpeng He, Lijian Li, Tianxiang Zhan, Wenpin Jiao, Chi-Man Pun
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024) 2024 CCF B Regular Paper (Oral)
Capturing feature information effectively is of great importance in the field of computer vision. With the development of convolutional neural networks, concepts like residual connection and multiple scales promote continual performance gains in diverse deep learning vision tasks. In this paper, novel residual feature-reutilization inception and split-residual feature-reutilization inception are proposed to improve performance on various vision tasks. It consists of four parallel branches, each with convolutional kernels of different sizes. These branches are interconnected by hierarchically organized channels, similar to residual connections, facilitating information exchange and rich dimensional variations at different levels. This structure enables the acquisition of features with varying granularity and effectively broadens the span of the receptive field in each network layer. Moreover, according to the network structure designed above, split-residual feature-reutilization inceptions can adjust the split ratio of the input information, thereby reducing the number of parameters and guaranteeing the model performance. Specifically, in image classification experiments based on popular vision datasets, such as CIFAR10 (97.94%), CIFAR100 (85.91%), Tiny Imagenet (70.54%) and ImageNet (80.83%), we obtain state-of-the-art results compared with other modern models under the premise that the models’ sizes are approximate and no additional data is used.
Uncertainty-aware Evidential Fusion-based Learning for Semi-supervised Medical Image Segmentation
arXiv 2024 Preprint
Although the existing uncertainty-based semi-supervised medical segmentation methods have achieved excellent performance, they usually only consider a single uncertainty evaluation, which often fails to solve the problem related to credibility completely. Therefore, based on the framework of evidential deep learning, this paper integrates the evidential predictive results in the cross-region of mixed and original samples to reallocate the confidence degree and uncertainty measure of each voxel, which is realized by emphasizing uncertain information of probability assignments fusion rule of traditional evidence theory. Furthermore, we design a voxel-level asymptotic learning strategy by introducing information entropy to combine with the fused uncertainty measure to estimate voxel prediction more precisely. The model will gradually pay attention to the prediction results with high uncertainty in the learning process, to learn the features that are difficult to master. The experimental results on LA, Pancreas-CT, ACDC and TBAD datasets demonstrate the superior performance of our proposed method in comparison with the existing state of the arts.
EPL: Evidential Prototype Learning for Semi-supervised Medical Image Segmentation
arXiv 2024 Preprint
Although current semi-supervised medical segmentation methods can achieve decent performance, they are still affected by the uncertainty in unlabeled data and model predictions, and there is currently a lack of effective strategies that can explore the uncertain aspects of both simultaneously. To address the aforementioned issues, we propose Evidential Prototype Learning (EPL), which utilizes an extended probabilistic framework to effectively fuse voxel probability predictions from different sources and achieves prototype fusion utilization of labeled and unlabeled data under a generalized evidential framework, leveraging voxel-level dual uncertainty masking. The uncertainty not only enables the model to self-correct predictions but also improves the guided learning process with pseudo-labels and is able to feed back into the construction of hidden features. The method proposed in this paper has been experimented on LA, Pancreas-CT and TBAD datasets, achieving the state-of-the-art performance in three different labeled ratios, which strongly demonstrates the effectiveness of our strategy.
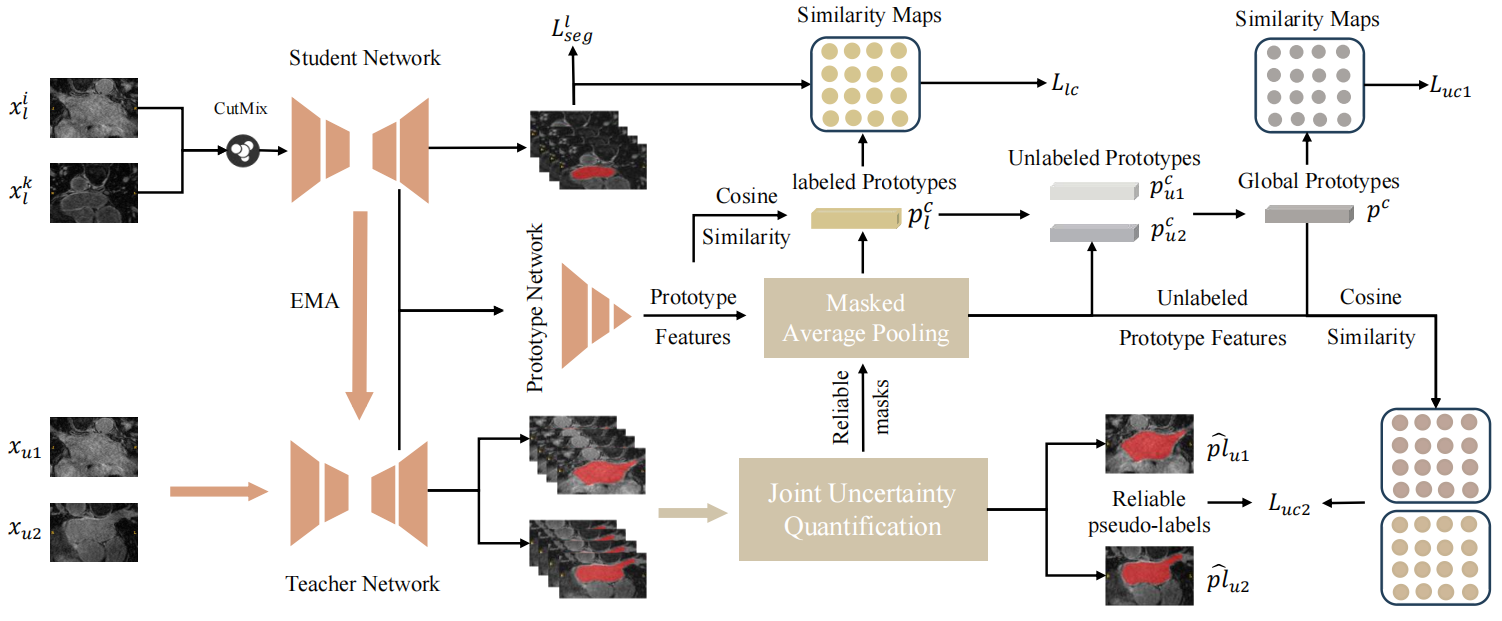
Efficient Prototype Consistency Learning in Semi-Supervised Medical Image Segmentation via Joint Uncertainty and Data Augmentation
Lijian Li, Yuanpeng He, Chi-Man Pun
IEEE International Conference on Bioinformatics and Biomedicine 2024 (IEEE BIBM 2024) 2024 CCF B Regular Paper
Recently, prototype learning has emerged in semi-supervised medical image segmentation and achieved remarkable performance. However, the scarcity of labeled data limits the expressiveness of prototypes in previous methods, potentially hindering the complete representation of prototypes for class embedding. To overcome this issue, we propose an efficient prototype consistency learning via joint uncertainty quantification and data augmentation (EPCL-JUDA) to enhance the semantic expression of prototypes based on the framework of Mean-Teacher. The concatenation of original and augmented labeled data is fed into student network to generate expressive prototypes. Then, a joint uncertainty quantification method is devised to optimize pseudo-labels and generate reliable prototypes for original and augmented unlabeled data separately. High-quality global prototypes for each class are formed by fusing labeled and unlabeled prototypes, which are utilized to generate prototype-to-features to conduct consistency learning. Notably, a prototype network is proposed to reduce high memory requirements brought by the introduction of augmented data. Extensive experiments on Left Atrium, Pancreas-NIH, Type B Aortic Dissection datasets demonstrate EPCL-JUDA's superiority over previous state-of-the-art approaches, confirming the effectiveness of our framework. The code will be released soon.
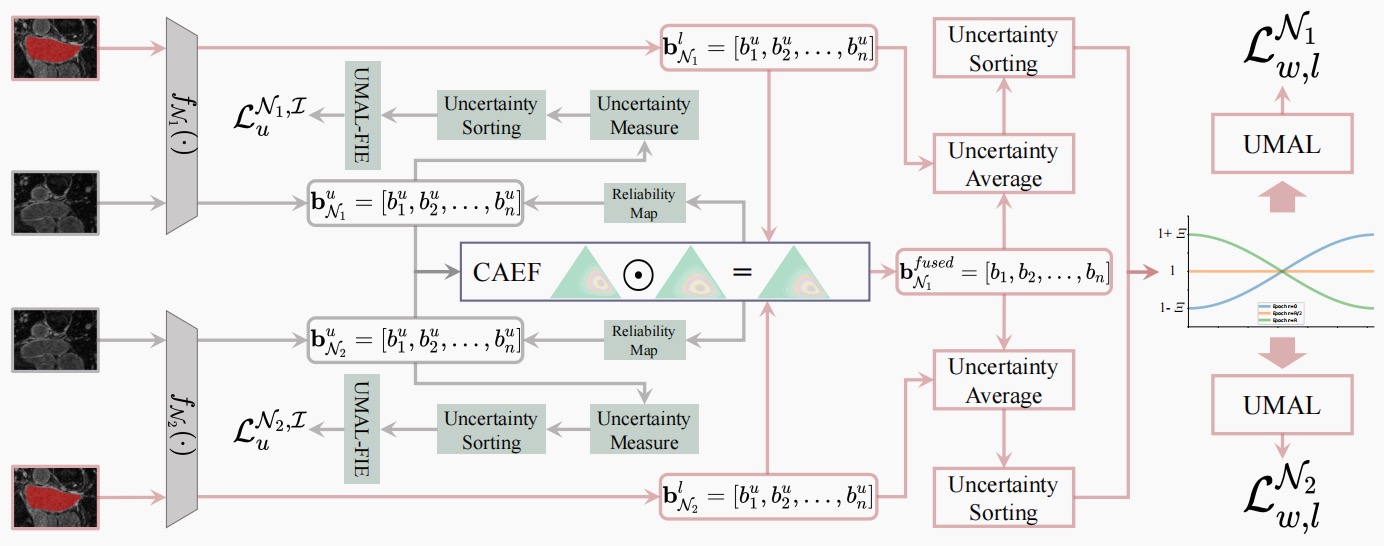
Mutual Evidential Deep Learning for Semi-supervised Medical Image Segmentation
Yuanpeng He, Yali Bi, Lijian Li, Chi-Man Pun, Wenpin Jiao, Zhi Jin
IEEE International Conference on Bioinformatics and Biomedicine 2024 (IEEE BIBM 2024) 2024 CCF B Regular Paper
Existing semi-supervised medical segmentation co-learning frameworks have realized that model performance can be diminished by the biases in model recognition caused by low-quality pseudo-labels. Due to the averaging nature of their pseudo-label integration strategy, they fail to explore the reliability of pseudo-labels from different sources. In this paper, we propose a mutual evidential deep learning (MEDL) framework that offers a potentially viable solution for pseudo-label generation in semi-supervised learning from two perspectives. First, we introduce networks with different architectures to generate complementary evidence for unlabeled samples and adopt an improved class-aware evidential fusion to guide the confident synthesis of evidential predictions sourced from diverse architectural networks. Second, utilizing the uncertainty in the fused evidence, we design an asymptotic Fisher information-based evidential learning strategy. This strategy enables the model to initially focus on unlabeled samples with more reliable pseudo-labels, gradually shifting attention to samples with lower-quality pseudo-labels while avoiding over-penalization of mislabeled classes in high data uncertainty samples. Additionally, for labeled data, we continue to adopt an uncertainty-driven asymptotic learning strategy, gradually guiding the model to focus on challenging voxels. Extensive experiments on five mainstream datasets have demonstrated that MEDL achieves state-of-the-art performance.
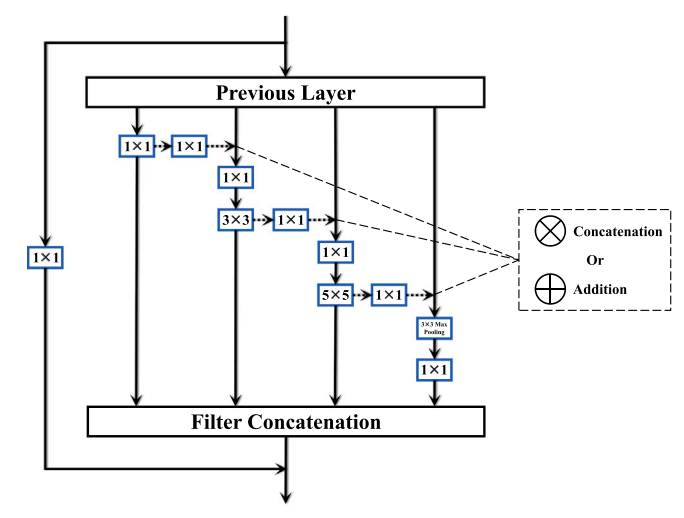
Residual Feature-Reutilization Inception Network
Yuanpeng He, Wenjie Song, Lijian Li, Tianxiang Zhan, Wenpin Jiao
Pattern Recognition 2024 中科院升级版1区 CCF B
Capturing feature information effectively is of great importance in the field of computer vision. With the development of convolutional neural networks, concepts like residual connection and multiple scales promote continual performance gains in diverse deep learning vision tasks. In this paper, novel residual feature-reutilization inception and split-residual feature-reutilization inception are proposed to improve performance on various vision tasks. It consists of four parallel branches, each with convolutional kernels of different sizes. These branches are interconnected by hierarchically organized channels, similar to residual connections, facilitating information exchange and rich dimensional variations at different levels. This structure enables the acquisition of features with varying granularity and effectively broadens the span of the receptive field in each network layer. Moreover, according to the network structure designed above, split-residual feature-reutilization inceptions can adjust the split ratio of the input information, thereby reducing the number of parameters and guaranteeing the model performance. Specifically, in image classification experiments based on popular vision datasets, such as CIFAR10 (97.94%), CIFAR100 (85.91%), Tiny Imagenet (70.54%) and ImageNet (80.83%), we obtain state-of-the-art results compared with other modern models under the premise that the models’ sizes are approximate and no additional data is used.
2022

NNDF A new neural detection network for aspect-category sentiment analysis
Lijian Li, Yuanpeng He, Li Li
International Conference on Knowledge Science, Engineering and Management (KSEM) 2022 CCF C
Aspect-category sentiment analysis (ACSA) is crucial for capturing and understanding sentiment polarities of aspect categories hidden behind in sentences or documents automatically. Nevertheless, existing methods have not modeled semantic dependencies of aspect terms and specified entity’s aspect category in sentences. In this paper, we propose a New Neural Detection Network, named NNDF in short, to enhance the ACSA performance. Specifically, representations of input sentences and aspect categories contained in our method are generated by a CNN-pooling-BiLSTM structure respectively, where sentences are represented based on their contextual words and aspect categories are represented based on word embeddings of entities category-specific. Then, a Transformer-based encoder is used to model implicit dependency of sentence contexts and aspect categories of entities in sentences. Finally, the embedding of aspect-category is learned by the novel bidirectional attention mechanism for the sentiment classification. Besides, experiments conducted on Restaurant and MAMS benchmark datasets for the task demonstrate that NNDF achieves more accurate prediction results as compared to several state-of-the-art baselines.
2021
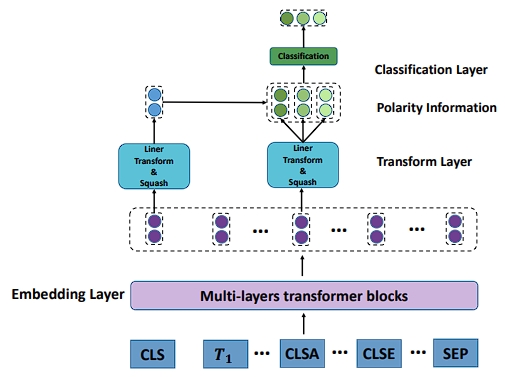
Transformer-based Relation Detect Model for Aspect-based Sentiment Analysis
Zixi Wei, Xiaofei Xu, Lijian Li, Kaixin Qin, Li Li
International Joint Conference on Neural Networks (IJCNN) 2021 CCF C
Aspect-based sentiment analysis (ABSA) aims to detect the sentiment polarities of a sentence with a given aspect. Aspect-term sentiment analysis (ATSA) is a subtask of ABSA, in ATSA, the aspect is given by aspect term: a word or a phrase in sentence. In previous work, most models apply attention mechanism or gating mechanism to capture the key part of the sentence and detect the sentiment polarity by classifying the weighted sum vector, which are regardless of the aspect information during the classification. However, same contexts may show different sentiment polarity with differnet aspects. For example, in sentence “The scene hunky waiters dub diner darling and it sounds like they mean it.” the context “dub diner dearling” shows negative polarity towards the aspect term “waiters”. But in sentence “The diner's husband dub diner darling.”, the same context would show neural polarity towards “husband”. The absent of aspect information would make model get a wrong result in some sentence. To solve this problem, we propose a model called Trasfomer-based context-aspect Relation Detect Model (TRDM), and add two special tokens “[CLSA]” and “[SEPA]” to specify the aspect term in the sentence. TRDM uses the embedding of two tyes of tokens (i.e. “[CLS]” and “[CLSA]”) for classification where “[CLS]” is used to represent the entire sentence in BERT. This scheme enable TRDM to combine the sentence information and aspect information in the step of sentiment polarity classification. We evaluate the performance of our model on two datasets: Restaurant dataset from SemEval2014 and MAMS from NLPCC 2020. Experiment results show that our model obtain noticeable improvement compared with state-of-art transfromer-based models.